





Les pages scannées par les moteurs de recherche ne représentent que 5 à 10% du Web. Pour explorer le “deep web”, les chercheurs de l’armée américaine ont développé un programme ultra-puissant, Memex, qui analyse et croise les données non indexées.
Les moteurs de recherche Google, Bing ou Yahoo! ne couvrent qu’une petite partie du Web – entre 5 et 10%. Sous le “web visible”, se dissimule ainsi le “web invisible”, ou “web profond”. Les robots des moteurs de recherche ne référencent que des pages statiques, liées à d’autres pages.
La grande partie de la Toile (264 fois plus vaste que le “web visible”) leur reste inaccessible, pour plusieurs raisons. Il peut s’agir de pages ou de documents trop volumineux pour être entièrement indexés. Il peut aussi s’agir de pages protégées par l’auteur (par exemple, le cas du Monde et de ses pages payantes), qui est capable d’interdire aux robots de scanner son site, en insérant dans le code de ses pages un fichier robot.txt.
Les pages peuvent aussi être protégées, et accessibles uniquement avec un mot de passe et un identifiant. Il faut aussi savoir que de nombreux sites, comme ceux des Universités par exemple, ne rendent accessibles leurs pages que via leur moteur de recherche interne – les pages sont générées dynamiquement, et les URL des pages ne sont pas statiques. Il s’agit donc d’un web “privé”, ou “opaque”, car volontairement inaccessible, ou alors difficilement “scannable”.
Le “dark web” ne concerne pas que les échanges illégaux (armes, drogues), le piratage, le téléchargement et autres activités criminelles. Le web non indexé par les moteurs comprend des bases de données très utiles pour les chercheurs, comme Lexis Nexis ou Dialog/ProQuest, ou encore des bibliothèques en ligne. Dans le web invisible, on retrouve aussi des sites scientifiques, tels que celui de la Nasa, des sites universitaires (Berkeley, Harvard), des sites de médias, ou encore les sites des grandes entreprises.
Rendre visible l’invisible
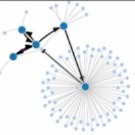
Pour explorer cette partie non visible de l’iceberg, le Darpa, le laboratoire de recherche de l’armée américaine, a mis au point un programme capable de mener des recherches thématiques dans des pages Web non indexées. “Memex” (pour “mémoire” et ‘index”) ne se borne pas à repérer et à classer les pages Web en fonction de leur popularité et de mots-clés : il analyse les pages non répertoriées de réseaux tels que Tor, établit entre autres des liens entre les pages selon les bandeaux publicitaires qu’elles partagent, et croise de nombreuses données. Il permet aussi de créer des visualisations dynamiques des recherches, sous la forme de frises chronologiques.
Le département américaine de Défense a déjà testé, avec succès, Memex pour surveiller les réseaux de prostitution lors du Super Bowl – le programme était capable de repérer les pages cachées promouvant des services sexuels, et de récupérer des données de géolocalisation, afin d’aider la police dans leurs enquêtes.
Salué par Barack Obama, l’outil développé par le Darpa pourrait aussi être utilisé dans d’autres activités – par exemple, dans le cas d’une épidémie comme Ebola, en repérant l’avancée géographique de données. Memex pourrait aussi, à terme, aider les recherches des internautes lambdas.
Le laboratoire de recherche précise sur son site que ce nouveau moteur de recherche ultra-puissant (dont la conception a coûté entre 10 et 20 millions de dollars) n’a pas l’intention de collecter des données personnelles, ou de désanonymiser des services anonymes.
Par Fabien Soyez









Réagissez à cet article
Vous avez déjà un compte ? Connectez-vous et retrouvez plus tard tous vos commentaires dans votre espace personnel.
Inscrivez-vous !
Vous n'avez pas encore de compte ?
CRÉER UN COMPTE