





Présentation
RÉSUMÉ
L’identification d’un procédé consiste en l’estimation d’un modèle mathématique permettant, notamment, la synthèse d’une loi de commande ou encore d’anticiper son comportement futur. Cette identification suppose la connaissance de signaux d’entrée-sortie du procédé et nécessite le choix de la structure du modèle. La représentation d’état est une de ces structures possibles.
Cet article présente la méthodologie pour l’estimation d’un modèle dans l’espace d’état: la structure du modèle,les algorithmes classiques pour l’estimation de modèles à temps discret, les variantes telles que celles pour l’estimation d’un modèle en temps réel, l’estimation de modèles à temps continu ou l’identification en boucle fermée.
Lire cet article issu d'une ressource documentaire complète, actualisée et validée par des comités scientifiques.
Lire l’articleABSTRACT
The identification of a dynamical process consists in the estimation of a mathematical model allowing the synthesis of a control law or the prediction of the future behavior of the system. This identification is based on the knowledge of experimental data and the choice of a structure for the model. A possible structure is the state space representation.
This article presents solutions for the estimation of a state space model : classical algo- rithms in the discrete-time domain and also solutions for real-time identification, solutions for continuous-time domain model identification and solutions for closed loop identification.
Auteur(s)
-
Mathieu POULIQUEN : Maître de Conférences - Université de Caen Normandie (France)
-
Eric PIGEON : Maître de Conférences - Université de Caen Normandie (France)
INTRODUCTION
La détermination du modèle d’un procédé dynamique est un problème essentiel dans de nombreuses disciplines scientifiques telles que l’automatique, l’économie, la médecine, etc.
La disposition d’un tel modèle permet, entre autres choses, une meilleure compréhension du procédé étudié, une analyse des interactions et relations de causalité entre différentes variables et grandeurs relatives au procédé, l’observation et la prédiction de certaines de ces variables.
Génériquement, deux procédures se distinguent pour l’élaboration d’un modèle. La première procédure consiste à décomposer le procédé en sous-systèmes élémentaires puis, via l’adjonction de lois élémentaires de la physique, de la finance, du vivant, etc., à établir un modèle dynamique de l’ensemble du procédé. Ce type de modélisation est appelé « modélisation boîte blanche ». Elle a deux inconvénients majeurs. Tout d’abord, elle requiert une connaissance approfondie de ces lois élémentaires et du comportement interne du système. Ensuite, elle induit souvent la détermination d’un modèle complexe, à base de dérivées partielles ou de paramètres inconnus par exemple, difficile à exploiter.
La seconde procédure pour l’élaboration d’un modèle consiste à réaliser une ou plusieurs expériences sur le procédé et en extraire un modèle dynamique cohérent. Cette seconde procédure nécessite d’agir spécifiquement sur le procédé (les variables par l’intermédiaire desquelles il est possible d’agir sur le procédé sont appelées les « entrées ») et de réaliser des mesures descriptives du comportement du procédé (les variables par l’intermédiaire desquelles il est possible d’observer le comportement du procédé sont appelées les sorties). Ce type de modélisation est appelé modélisation boîte noire ou identification. C’est ce type de modélisation qui nous intéresse ici.
La littérature fait état de nombreuses techniques pour la mise en oeuvre d’une telle procédure. L’essor majeur de ces techniques se situe dans les années 1960 au cours desquelles deux voies ont connu des développements importants. La première voie correspond aux méthodes d’identification de modèle sous forme de fonction de transfert (équations différentielles pour le modèle à temps continu ou équations aux différences pour les modèles à temps discret). Ces méthodes permettent uniquement la représentation du comportement externe du procédé, c’est à dire uniquement une description du comportement entrée-sortie. Elles ont été très largement étudiées et la littérature fait état de quelques ouvrages de référence en la matière.
Dans cet article, nous nous intéressons à la seconde voie. Elle correspond aux méthodes permettant l’estimation d’un modèle sous forme de représentation d’état, structure de modèle caractérisant le fonctionnement interne du procédé. Ces méthodes ont été en retrait dans les années 1970 et 1980 pour ensuite connaître un regain d’intérêt à partir des années 1990 sous l’appellation de « méthodes des sous-espaces ». Cette appellation vient du fait que ces méthodes sont basées sur une reconstruction du sous-espace vectoriel caractérisant le fonctionnement interne du procédé. Ces méthodes ont depuis atteint un certain degré de maturité, cette maturité se traduit par de nombreuses applications probantes en milieu industriel et académique ainsi que par une intégration de ces méthodes au sein de différents outils de calcul numérique pour l’ingénieur.
L’objectif de cet article est de présenter le principe fondateur de ces méthodes des sous-espaces pour les modèles à temps discret ainsi que de présenter quelques variantes, notamment pour les modèles à temps continu et les modèles variant dans le temps.
L'expertise technique et scientifique de référence
KEYWORDS
identification | Algorithms | mathematical model | State-space representation | subspace
DOI (Digital Object Identifier)
Cet article fait partie de l’offre
Automatique et ingénierie système
(141 articles en ce moment)
Cette offre vous donne accès à :
![]()
Une base complète d’articles
Actualisée et enrichie d’articles validés par nos comités scientifiques
![]()
Des services
Un ensemble d'outils exclusifs en complément des ressources
![]()
Un Parcours Pratique
Opérationnel et didactique, pour garantir l'acquisition des compétences transverses
![]()
Doc & Quiz
Des articles interactifs avec des quiz, pour une lecture constructive
Présentation
2. Identification de modèles sous forme de représentation d’état à temps discret en boucle ouverte
Dans ce chapitre, nous supposerons que le système opère en boucle ouverte. Le cas de la boucle fermée sera évoqué dans le chapitre suivant. En boucle ouverte, les méthodes d’identification pour l’estimation de modèle sous forme de représentation d’état sont structurées en 3 étapes :
-
étape 1 : conditionnement des données (§ 2.1) ;
-
étape 2 : estimation de l’ordre et de la matrice d’observabilité étendue (§ 2.2) ;
-
étape 3 : estimation des matrices d’état (§ 2.3).
Ces trois étapes sont détaillées dans la suite.
2.1 Étape 1 : conditionnement des données
La plupart des méthodes des sous-espaces utilisent des notations introduites dans . Sous cette formulation, le traitement des données est réalisé à partir de matrices de Hankel, organisant d’une part les données futures et, d’autre part, les données passées.
Les matrices de Hankel Y p et Y f de la séquence {y(t)}, respectivement les matrices des sorties passées et futures, sont définies comme suit :
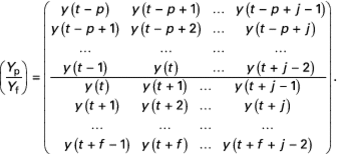
L'expertise technique et scientifique de référence
Cet article fait partie de l’offre
Automatique et ingénierie système
(141 articles en ce moment)
Cette offre vous donne accès à :
![]()
Une base complète d’articles
Actualisée et enrichie d’articles validés par nos comités scientifiques
![]()
Des services
Un ensemble d'outils exclusifs en complément des ressources
![]()
Un Parcours Pratique
Opérationnel et didactique, pour garantir l'acquisition des compétences transverses
![]()
Doc & Quiz
Des articles interactifs avec des quiz, pour une lecture constructive
Identification de modèles sous forme de représentation d’état à temps discret en boucle ouverte
BIBLIOGRAPHIE
-
(1) - LJUNG (L.) - System identification : theory for the user. - second edition. Prentice Hall (1999).
-
(2) - MOONEN (M.), et al - On and Off line identifications of linear state space models. - In : International Journal of Control 49.1, p. 219-232 (1989).
-
(3) - ZEIGER (H.P.), MC EWEN (A.J.) - Approximate linear realizations of given dimension via Ho’s algorithm. - In : IEEE Transaction on Automatic Control 19, p. 153 (1974).
-
(4) - VAN OVERSCHEE (P.), DE MOOR (B.) - Subspace identification for linear systems. Theory, implementation applications. - Leuven : Kluver Academic Publishers (1996).
-
(5) - VERHAEGEN (M.) - Identification of the deterministic part of MIMO state space models given in innovations form from input output data. - In : Automatica 30.1, p. 61-74 (1994).
-
(6)...
DANS NOS BASES DOCUMENTAIRES
L'expertise technique et scientifique de référence
Cet article fait partie de l’offre
Automatique et ingénierie système
(141 articles en ce moment)
Cette offre vous donne accès à :
![]()
Une base complète d’articles
Actualisée et enrichie d’articles validés par nos comités scientifiques
![]()
Des services
Un ensemble d'outils exclusifs en complément des ressources
![]()
Un Parcours Pratique
Opérationnel et didactique, pour garantir l'acquisition des compétences transverses
![]()
Doc & Quiz
Des articles interactifs avec des quiz, pour une lecture constructive
