





Présentation
Auteur(s)
-
François BOUTIN : Professeur des Universités, Université Montpellier 1
Lire cet article issu d'une ressource documentaire complète, actualisée et validée par des comités scientifiques.
Lire l’articleL'expertise technique et scientifique de référence
MOTS-CLÉS
bibliographie | recherche en langage naturel | requête booléenne | exploration | recherche itérative | thésaurus | descripteur MeSH | Medline | PubMed
DOI (Digital Object Identifier)
Cet article fait partie de l’offre
Management et ingénierie de l'innovation
(424 articles en ce moment)
Cette offre vous donne accès à :
![]()
Une base complète d’articles
Actualisée et enrichie d’articles validés par nos comités scientifiques
![]()
Des services
Un ensemble d'outils exclusifs en complément des ressources
![]()
Un Parcours Pratique
Opérationnel et didactique, pour garantir l'acquisition des compétences transverses
![]()
Doc & Quiz
Des articles interactifs avec des quiz, pour une lecture constructive
Présentation
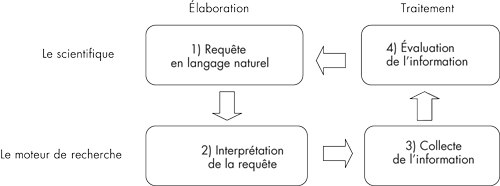
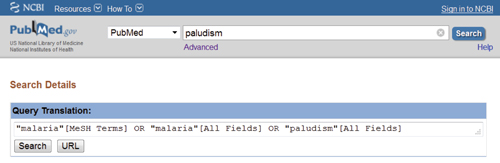
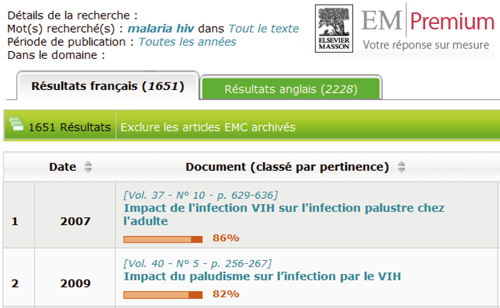
Depuis l’avènement de Google, la recherche d’information par interrogation s’est imposée auprès du grand public au détriment de la recherche par catalogue (initiée par Yahoo!). De nombreux scientifiques sont séduits par la simplicité d’interrogation de bases de données en langage naturel, au grand désespoir des documentalistes qui prônent l’utilisation de requêtes structurées pour mener des recherches bibliographiques de qualité.
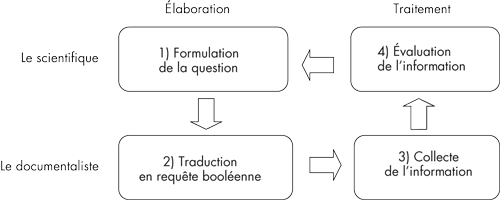
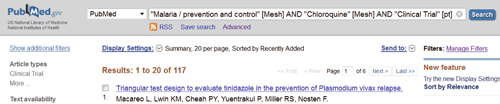
Nous présentons ici l’intérêt de méthodes exploratoires de recherche bibliographique, qui concilient à la fois simplicité et efficacité en favorisant l’utilisation d’un vocabulaire contrôlé et l’interaction de l’utilisateur pour la construction itérative de requêtes.
Étapes :
L'expertise technique et scientifique de référence
Cet article fait partie de l’offre
Management et ingénierie de l'innovation
(424 articles en ce moment)
Cette offre vous donne accès à :
![]()
Une base complète d’articles
Actualisée et enrichie d’articles validés par nos comités scientifiques
![]()
Des services
Un ensemble d'outils exclusifs en complément des ressources
![]()
Un Parcours Pratique
Opérationnel et didactique, pour garantir l'acquisition des compétences transverses
![]()
Doc & Quiz
Des articles interactifs avec des quiz, pour une lecture constructive
Fiches à lire
Faq
Aller plus loin
Sites Internet
PubMed : http://www.ncbi.nlm.nih.gov/pubmed, interface officielle de Medline (NLM)
MeSH : http://www.ncbi.nlm.nih.gov/mesh, interface d’accès au thesaurus MeSH (NLM)
EM-Premium : http://www.em-premium.com, plate-forme d’Elsevier Masson permettant d’accéder aux articles de l’Encyclopédie médico-chirurgicale
BDSP : http://www.bdsp.ehesp.fr/Base, site de la Banque de données en santé publique
Google Scholar : http://scholar.google.fr, interface bibliographique de Google
GoPubMed : http://www.gopubmed.org, interface de veille documentaire de Medline
BibliMed : http://www.biblimed.com, interface alternative de Medline
Bibliographie
[1] J. R. Herskovic, L. Y. Tanaka, W. Hersh, et E. V. Bernstam, « A day in the life of PubMed: analysis of a typical day’s query log », J. Am. Med. Informatics Assoc. JAMIA, vol. 14, n° 2, p. 212‑220, avr. 2007
[2] E. Kolmayer, « Démarche d’interrogation documentaire et navigation », in Hypermédias et apprentissages, Poitiers, 1998, p. 89-96
[3] R. W. White, G. Marchionini, et G. Muresan, « Evaluating exploratory search systems: Introduction to special topic issue of information processing and management », Information Processing & Management, vol. 44, n° 2, p. 433-436, mars 2008
Abréviations et acronymes
- MeSH (Medical Subject Headings) : vocabulaire contrôlé utilisé pour l’indexation des articles
- NLM (National Library of Medicine) : éditeur de Medline et du MeSH
Cet article fait partie de l’offre
Management et ingénierie de l'innovation
(424 articles en ce moment)
Cette offre vous donne accès à :
![]()
Une base complète d’articles
Actualisée et enrichie d’articles validés par nos comités scientifiques
![]()
Des services
Un ensemble d'outils exclusifs en complément des ressources
![]()
Un Parcours Pratique
Opérationnel et didactique, pour garantir l'acquisition des compétences transverses
![]()
Doc & Quiz
Des articles interactifs avec des quiz, pour une lecture constructive
