


Pourquoi est-ce important ? La plupart des gens utilisent des moteurs de recherche pour trouver ce qu'ils cherchent sur internet. Tout site Internet se doit donc d'être bien être référencé, sinon il n'aura aucun visiteur....
Choisir les bon mots-clés est relativement facile, par contre avoir un indice PageRank élevé est plus compliqué. L’indice PageRank est ce qui définit la position dans les pages de résultat des moteurs de recherche (pour Google évidemment, mais les autres moteurs utilisent maintenant plus ou moins le même genre d’algorithme). Il est donc très important de bien comprendre le fonctionnement de ce type d’algorithme pour espérer apparaître sur la première page de résultat (la seule lue dans 95 % des cas) ou au moins figurer parmi les premiers. Je vous propose dans cet article d’éclairer le fonctionnement de cet algorithme ainsi qu’un applet Java permettant d’expérimenter ce type d’analyse. Il s’agit bien sur d’une version simplifiée, mais cela permet de comprendre quand même beaucoup de choses.
Petit historique
Les premiers moteurs de recherche (AltaVista ou Yahoo) ne faisaient qu’indexer, c’est-à-dire trouver toutes les pages contenant le ou les mots-clés recherchés. On pouvait retrouver les pages contenant un mot-clé donné, mais les résultats n’étaient pas triés efficacement. Le nombre de fois où apparaissait le mot-clé faisait apparaître la page en haut de la liste de résultats, ce qui n’est pas pertinent. Le nombre de répétions du mot-clé n’est pas un critère intéressant car aisément falsifiable. Il faut faire une analyse plus fine du Web pour être capable de mesurer automatiquement l’importance de chaque site. Sergey Brin et Lawrence Page, étudiants à l’Université Standford (États-Unis), ont trouvé une solution aussi originale que simple : utiliser l’information des liens entre les pages pour mesurer l’importance des sites, et être alors capable de classer correctement les résultats d’une recherche de mots-clés. Cet algorithme s’appelle le « PageRank », et est finalement assez simple (niveau deuxième année d’étude supérieure). Sergey et Lawrence ont créé l’entreprise Google, actuellement le meilleur moteur de recherche du Web. Google est devenu très rapidement (et sans aucune publicité) un des moteurs les plus influents du Web. Les autres (Yahoo etc.) on rapidement suivi, mais bien sûr, cette avancée technologique a permis à Google d’être les « first to market » et donc de prendre une longueur d’avance sur la concurrence. Google essaye de garder cet avantage, en proposant toujours de réelles avancées technologiques, et bien sûr en améliorant l’algorithme PageRank, devenu un secret industriel aussi bien gardé que la fameuse recette exacte du Coca-Cola. La version que j’expose ici reste est une approche à la fois simple et instructive pour comprendre les bases du référencement, vu que maintenant tous les moteurs de recherche utilisent des variantes de cet algorithme.
Le PageRank : comment ça marche
L’algorithme PageRank calcule un indice de popularité associé à chaque page Web. C’est cet indice qui est utilisé pour trier le résultat d’une recherche de mots-clés. L’indice est défini ainsi : « L’indice de popularité d’une page est d’autant plus grand qu’elle a un grand nombre de pages populaires la référençant (ayant un lien vers elle) ». Cette définition est autoréférente car pour connaître l’indice d’une page, il faut d’abord connaître l’indice des pages ayant un lien vers elle… Il existe cependant un moyen assez simple d’approcher une valeur numérique de l’indice.
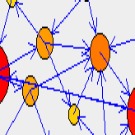
Tout d’abord il faut voir le Web comme un graphe. Chaque page est un noeud du graphe, chaque lien entre les pages est un arc entre deux noeuds.
Une manière commode pour représenter de telles relations est d’utiliser une matrice (= un tableau) : chaque ligne et colonne représentent un noeud (donc un site) et chaque case de la matrice représente la présence d’un lien entre les deux pages correspondantes.
|
|
Site No 0 |
Site No 1 |
Site No 2 |
Site No 3 |
|
Site No 0 |
0 |
0 |
0 |
0 |
|
Site No 1 |
1 |
0 |
0 |
0 |
|
Site No 2 |
1 |
0 |
0 |
0 |
|
Site No 3 |
1 |
0 |
1 |
0 |
Note : Pour savoir si il y a un lien entre deux sites A et B, il suffit de regarder le contenu de la case positionné en ligne A et colonne B : 0 signifie qu’il n’y a pas de lien, 1 qu’il y en a un.
Nous allons appeler cette matrice M. On représente la probabilité de présence d’un internaute sur tous les noeuds de notre graphe par un vecteur V. Dire que l’internaute est sur la page « 1 » s’écrit : V = (0 1 0 0). (Attention, on commence à compter les pages par 0, c’est donc bien la deuxième valeur qui est à 1 dans ce vecteur).
V' = V*M
on obtient un vecteur V’ = (1 0 0 0), c’est justement la probabilité de présence de l’internaute sur les pages : après un clic, l’internaute se retrouve forcement sur la page « 0 ». Il a suivi l’unique lien sortant de la page « 1 », allant vers la page « 0 ». On peut alors réitérer l’opération et multiplier ce vecteur résultat par M pour voir où se situera l’internaute lors du clic suivant, et ainsi de suite…
Si on faisait partir notre internaute de la page « 3 » : V = (0 0 0 1) le produit V par M donne (1 0 1 0), la somme des composante fait alors 2, cela est gênant pour représenter une probabilité de présence… . Dans la mesure où il impossible de savoir quel lien aura le plus de succès, on va considérer qu’ils ont tous la même probabilité d’être suivis, cela revient à normaliser la matrice (diviser chaque composante par la somme des valeurs de la ligne correspondante), le problème est résolu. La matrice devient alors :
|
|
Site No 0 |
Site No 1 |
Site No 2 |
Site No 3 |
|
Site No 0 |
0 |
0 |
0 |
0 |
|
Site No 1 |
1 |
0 |
0 |
0 |
|
Site No 2 |
1 |
0 |
0 |
0 |
|
Site No 3 |
1/2 |
0 |
1/2 |
0 |
Notez que la somme de chaque ligne fait bien 1, et que le produit V * M donne alors V’ = (½ 0 ½ 0) et représente alors correctement les probabilités de présence de l’internaute, partant de la page « 3 » et après avoir suivi un lien (« 1clic »). Si on réitère l’opération , c’est à dire V’*M, on obtient (1 0 0 0) au bout du deuxième « clic » de l’internaute. Si on continue, on voit bien que le résultat ne changera plus… L’internaute est bloqué sur la page « 0 ». Cela n’est pas très réaliste, on considérera alors que l’internaute repart sur une autre page, choisie au hasard. Cela revient à ajouter aux pages « cul-de-sac » des liens vers toutes les autres pages. Du point de vue de la matrice, cela revient à trouver les lignes qui n’ont que des 0 et les remplacer par des lignes avec 1/3 (dans ce cas précis) dans toutes les cases sauf sur la diagonale (lien d’une page vers elle-même). Pourquoi 1/3 ? Tout simplement par ce qu’il y a 4 pages et qu’on considère que l’internaute reprendra son parcours aléatoirement sur n’importe quelle autre page (4 (toutes les pages) – 1 (celle ou il est actuellement « bloqué ») = 3).
Le processus, tel qu’on l’a défini, permet maintenant de modéliser raisonnablement un déplacement aléatoire d’internautes sur le réseau de pages, modélisé par un graphe. Pour obtenir une vision globale et impartiale de la popularité des pages en fonction des liens qu’elles ont entre elles, il suffit maintenant de supposer que les internautes se répartissent initialement uniformément sur tout le réseau et on les laisse se déplacer jusqu’à ce que leur répartition (le vecteur V) se stabilise au fur et à mesure des itérations de multiplication avec M. Dit autrement, on commence avec un vecteur V dont toutes les composantes sont égales a 1/N, N étant le nombre total de pages (ou noeuds du graphe). Ensuite, on multiplie itérativement V par M jusqu’à ce que le valeur du vecteur V n’évolue plus. On regarde alors la répartition des internautes sur le graphe, cela nous donne l’indice PageRank : plus il est élevé, plus il y a d’internautes sur la page, et donc plus la page est populaire…
Une recherche se décompose alors en deux étapes :
- la sélection des pages contenant les mots-clés de la requête
- le classement, par ordre décroissant, des pages concernées en fonction de leur valeur de PageRank. Cette valeur aura bien sûr été calculée précédemment et n’est pas recalculée à chaque requête.
Ces deux actions combinées font un moteur de recherche plutôt efficace…
On voit que algorithme PageRank (simplifié) est finalement assez simple :
- initialisez toutes les composantes de V à 1/N (N étant le nombre de pages ou noeud du graphe)
- calculez V’= V*M, (où M est la matrice représentant le graphe)
- copiez le contenu de V’ dans V
- reprenez en 2 sauf si les deux vecteurs V et V’ sont très proches, dans ce cas l’algorithme est terminé
V ou V’ (puisqu’il sont proches la fin de l’algorithme) contiennent les indices PageRank de chaque page. En pratique, les valeurs de PageRank sont modifiés pour donner des valeurs entre 0 et 10, pour que cela soit plus « parlant ». Cela n’a que peu d’importance en pratique, dans la mesure où on utilise cette valeur uniquement pour la comparaison entre les différents sites concernés par une recherche de mots clés.
Par Hubert Wassner, professeur d’informatique à l’ESIEA et auteur d’un blog.









Réagissez à cet article
Connectez-vous
Vous avez déjà un compte ? Connectez-vous et retrouvez plus tard tous vos commentaires dans votre espace personnel.
Vous n'avez pas encore de compte ?
Inscrivez-vous !